Opensearch 구성은 cluster setting API에서 설정할 수 있다.
특정 부분은 opensearch.yml 파일을 수정하고 다시 시작해야되는 부분이 있는데, 이 특정 부분을 제외하고는 가능하면 cluster setting API를 사용하는 것이 좋다. cluster setting API는 클러스터 내 전체 노드의 설정을 적용하지만 opensearch.yml파일을 수정하는 것은 각각의 노드 설정을 변경하는 것이 된다.
opensearch.yml 파일을 수정해야되는 특정부분은 네트워킹, 클러스터 구성, 로컬 파일 시스템에 대한 수정 작업이 이루어질 때이다.
Opensearch에서 데이터를 검색 및 집계하기 전에 클러스터 생성부터 이루어져야 한다.
단일 노드 또는 다중 노드 클러스터로 작동할 수 있는데, 아래에는 다중 노드 클러스터의 기본 아키텍처 예시이다.
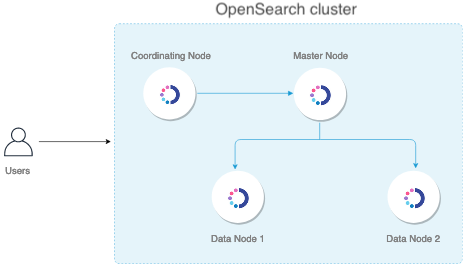
:: 노드 유형
| Node Type | Description | Best Practices for Production |
| Master | 전체적인 클러스터 상태의 유지관리 및 운영을 관장하는 노드. 인덱스를 생성, 삭제, 노드의 추가 및 삭제 추적, 각 노드의 health check, 노드의 샤드 할당 등을 담당한다. |
3개의 영역의 3개의 전용 마스터 노드는 거의 모든 프로덕션 사용 사례에 적합하다. 이 구성은 클러스터가 쿼리 요청을 잃지 않도록 한다. 두 개의 노드는 한 노드가 다운되거나 유지 관리가 필요한 경우를 제외하고 대부분의 시간 동안 유휴 상태 로 지속된다. |
| Master-Eligible | Master-eligible 노드들 중 투표를 통해 하나를 Master 노드로 선출한다. | |
| Data | 데이터를 저장하고 검색한다. 로컬 샤드에서 모든 데이터 관련 작업 ( 인덱싱, 검색, 집계 )을 수행한다. 클러스터의 작업자 노드로서 다른 노드 유형보다 많은 디스크 공간을 필요로 한다. |
데이터 노드를 추가할 때 각 노드들의 균형을 유지해야 한다. 예를 들어, 세 개의 영역이 있는 경우 각 영역에 하나씩 데이터 노드를 추가해야 한다. 스토리지 및 RAM이 많이 사용되는 노드를 사용하는 것이 좋다. |
| Ingest | 데이터를 클러스터에 저장하기 전에 전처리를 한다. 인덱스에 데이터를 추가하기 전에 데이터를 변환(가공)하는 수집 파이프라인을 실행한다. | 많은 데이터를 수집하고 복잡한 수집 파이프라인을 실행할 계획이라면 이 노드를 쓰는 것이 좋다. 선택적으로 데이터 노드에서 인덱싱을 off하여 데이터 노드가 검색 및 집계에만 사용되도록 할 수도 있다. |
| Coordinating | 클라이언트 요청을 데이터 노드의 샤드에 위임하고 결과를 수집하여 하나의 최종 결과로 집계한 다음 이 결과를 클라이언트에 다시 보내는 작업을 한다. | 검색이 많은 워크로드에 대한 병목 현상을 방지하려면 몇 개의 전용 coordinating 노드가 적합하다. 가능한 많은 코어가 있는 CPU를 사용하는 것이 좋다. |
이러한 모든 노드 유형은 벤치마크 테스트 도구인 Rally를 통해 소규모 샘플 클러스터를 provisioning하고 다양한 워크로드 및 구성으로 테스트를 해보는 것이 좋다.
** Rally : https://esrally.readthedocs.io/en/stable/
Rally 2.3.1 — Rally 2.3.1 documentation
You want to benchmark Elasticsearch? Then Rally is for you. It can help you with the following tasks: We have also put considerable effort in Rally to ensure that benchmarking data are reproducible. License This software is licensed under the Apache Licens
esrally.readthedocs.io
:: 클러스터 기본 설정
클러스터 기본설정은 config/opensearch.yml 파일 수정을 통해 진행한다.
1. 클러스터의 이름 설정
opensearch.yml에 cluster.name 부분 변경.
2. 클러스터의 각 노드에 대한 노드 속성 설정
// 마스터 노드
node.name: <node-name>
node.roles: [ master ]
// 2개의 데이터 노드 설정
node.name: opensearch-d1 (이름 예시)
node.name: opensearch-d2
// 데이터 수집에도 사용할 master-eligible노드로 만들 수 있습니다.
node.roles: [ data, ingest ]
// coordinating 노드
node.name: <node-name>
node.roles: [] // 기본이 coordinating 노드이므로 빈 값으로 설정
3. 클러스터를 특정 IP 주소에 binding
network_host는 노드를 바인드하는데 사용되는 IP 주소를 정의한다.
default로 Opensearch는 클러스터를 단일 노드로 제한하는 localhost를 수신한다.
IPv4나 IPv6 여부와 상관없이 `_local_`이나 `_site_`를 loopback(127.0.0.1)이나 site-local 주소에 바인드하기 위해 사용할 수 있다.
network.host: [_local_, _site_]
// 다중 노드 클러스터 구성 시
network.host: <IP address of the node>
4. 클러스터에 대한 discovery 호스트 구성
// 일반적으로 모든 master-eligible 노드를 해당 어레이에 추가할 수 있다.
discovery.seed_hosts: ["<private IP of opensearch-d1>", "<private IP of opensearch-d2>", "<private IP of opensearch-c1>"]
// 여기까지 구성을 마쳤다면 opensearch 서비스 시작 후 아래 커맨드로 구성한 모든 노드 상태를 볼 수 있다.
curl -XGET https://<private-ip>:9200/_cat/nodes?v -u 'admin:admin' --insecure
5. 샤드 할당 인식 및 강제 인식 구성
노드가 여러 지리적 영역에 분산되어 있는 경우 모든 복제본 샤드를 기본 샤드와 다른 영역에 할당하도록 샤드 할당 인식을 구성할 수 있습니다.
샤드 할당 인식을 사용하면 한 영역의 노드들이 장애가 발생해도 복제본의 샤드들이 다른 영역에도 있다는 걸 보증할 수 있습니다.
이것은 데이터가 개별 노드 오류를 넘어 영역 오류에서도 살아 남을 수 있도록 합니다.
// opensearch-d1의 영역 설정
node.attr.zone: zoneA
// opensearch-d2의 영역 설정
node.attr.zone: zoneB
// 클러스터 설정 업데이트
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "zone"
}
}
persistent 또는 transient 설정 을 사용할 수 있습니다 . persistent는 클러스터 재부팅 후에도 설정이 그대로 유지됩니다 . transient 설정은 클러스터 재부팅을 하게 되면 유지되지 않습니다.
샤드 할당 인식은 여러 영역에서 기본 샤드와 복제본 샤드를 분리하려고 시도합니다. 그러나 하나의 영역만 사용할 수 있는 경우, OpenSearch는 복제본 샤드를 남아 있는 유일한 영역에 할당하게 됩니다.
또 다른 옵션은 기본 및 복제본 샤드가 동일한 영역에 할당되지 않도록 하는 것입니다. 이것을 강제 인식이라고 합니다.
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "zone",
"cluster.routing.allocation.awareness.force.zone.values":["zoneA", "zoneB"]
}
}이 경우 데이터 노드에 장애가 발생하면 강제 인식이 동일한 영역의 노드에 복제본을 할당하지 않습니다. 대신 클러스터는 노란색 상태가 되고 다른 영역의 노드가 온라인 상태가 될 때만 복제본을 할당합니다.
6. hot-warm 아키텍처 설정
먼저 데이터를 빠르고 비용이 많이 드는 핫 노드에 인덱싱하고 일정 기간 후에 데이터를 느리고 저렴한 warm 노드로 이동하는 hot-warm 아키텍처를 설계할 수 있습니다.
거의 업데이트하지 않는 시계열 데이터를 분석하고 더 오래된 데이터를 더 저렴한 스토리지에 저장하려는 경우 이 아키텍처가 적합할 수 있습니다.
이 아키텍처는 스토리지 비용을 절약하는 데 도움이 됩니다. 핫 노드 수를 늘리고 빠르고 값비싼 스토리지를 사용하는 대신 자주 액세스하지 않는 데이터에 대해 웜 노드를 추가할 수 있습니다.
hot-warm 스토리지 아키텍처를 구성하려면 temp 속성을 opensearch-d1 및 opensearch-d2에 각각 추가합니다.
node.attr.temp: hot
node.attr.temp: warm// 핫 노드에 인덱스 추가
PUT newindex
{
"settings": {
"index.routing.allocation.require.temp": "hot"
}
}// 인덱스에 대한 샤드 할당 상태
GET _cat/shards/newindex?v
index shard prirep state docs store ip node
new_index 2 p STARTED 0 230b 10.0.0.225 opensearch-d1
new_index 2 r UNASSIGNED
new_index 3 p STARTED 0 230b 10.0.0.225 opensearch-d1
new_index 3 r UNASSIGNED
new_index 4 p STARTED 0 230b 10.0.0.225 opensearch-d1
new_index 4 r UNASSIGNED
new_index 1 p STARTED 0 230b 10.0.0.225 opensearch-d1
new_index 1 r UNASSIGNED
new_index 0 p STARTED 0 230b 10.0.0.225 opensearch-d1
new_index 0 r UNASSIGNED
위 예제에서 모든 primary 샤드들은 핫 노드인 opensearch-d1에 할당됩니다. 그러나 모든 복제본 샤드는 할당이 되지 않는데, 그 이유는 우리가 오직 핫 노드에게만 할당되도록 강제했기 때문입니다.
// warm 노드에 인덱스 추가
PUT oldindex
{
"settings": {
"index.routing.allocation.require.temp": "warm"
}
}// 인덱스에 대한 샤드 할당 상태
GET _cat/shards/oldindex?v
index shard prirep state docs store ip node
old_index 2 p STARTED 0 230b 10.0.0.74 opensearch-d2
old_index 2 r UNASSIGNED
old_index 3 p STARTED 0 230b 10.0.0.74 opensearch-d2
old_index 3 r UNASSIGNED
old_index 4 p STARTED 0 230b 10.0.0.74 opensearch-d2
old_index 4 r UNASSIGNED
old_index 1 p STARTED 0 230b 10.0.0.74 opensearch-d2
old_index 1 r UNASSIGNED
old_index 0 p STARTED 0 230b 10.0.0.74 opensearch-d2
old_index 0 r UNASSIGNED
이 경우 모든 기본 샤드는 opensearch-d2에 할당됩니다. 다시 말하지만, 하나의 웜 노드만 있기 때문에 모든 복제본 샤드가 할당되지 않게 됩니다.
index.routing.allocation.require.temp 값을 hot으로 설정하는 인덱스 템플릿을 이용할 수도 있습니다. 이 방법은 가장 최근의 데이터를 hot 노드에 저장하도록 합니다.
또한, 인덱스 상태 관리 플러스인(Index State Management (ISM))을 사용하여 인덱스의 주기를 관리할 수 있고, 특정 주기가 되면 warm 노드 상태로 변경하도록 할 수 있습니다.
'OpenSearch (ElasticSearch)' 카테고리의 다른 글
| [6] 데이터 스트림 (0) | 2022.02.25 |
|---|---|
| [5] 인덱스 별칭 (aliases) (0) | 2022.02.22 |
| [4] 인덱스 데이터 (0) | 2022.02.18 |
| [3] 인덱스 생성과 설정 예제 (0) | 2022.02.17 |
| [1] OpenSearch란? Opensearch와 일반 RDB 비교 (0) | 2022.02.12 |



